
![]()
The TACO specification
The file format ahead Tortilla.
The terms “MUST”, “MUST NOT”, “REQUIRED”, “SHALL”, “SHALL NOT”, “SHOULD”, “SHOULD NOT”, “RECOMMENDED”, “MAY”, and “OPTIONAL” in this document follow the definitions from RFC 2119.
The term “data user” refers to any individual or system accessing the data, “data provider” refers to the entity responsible for offering the data.
Overview
A TACO is a specification that extends the common structure of Tortilla files. TACO is inspired by the STAC Collection and includes additional fields to enable the automatic generation of Croissant, DataCite metadata, and Datacards.
TACO is designed around the FAIR principles:
- Findability: EO data is not structured for easy discovery. To improve dataset accessibility on platforms like Google Dataset Search, DataCite Search, and OpenAIRE Explore, data providers are typically required to understand and implement multiple specifications, such as STAC Collection, Croissant, and DataCite. The TACO Toolbox simplifies this process by providing offering a well-defined Pydantic schema, enabling seamless automatic conversion into these specifications, or all three simultaneously.
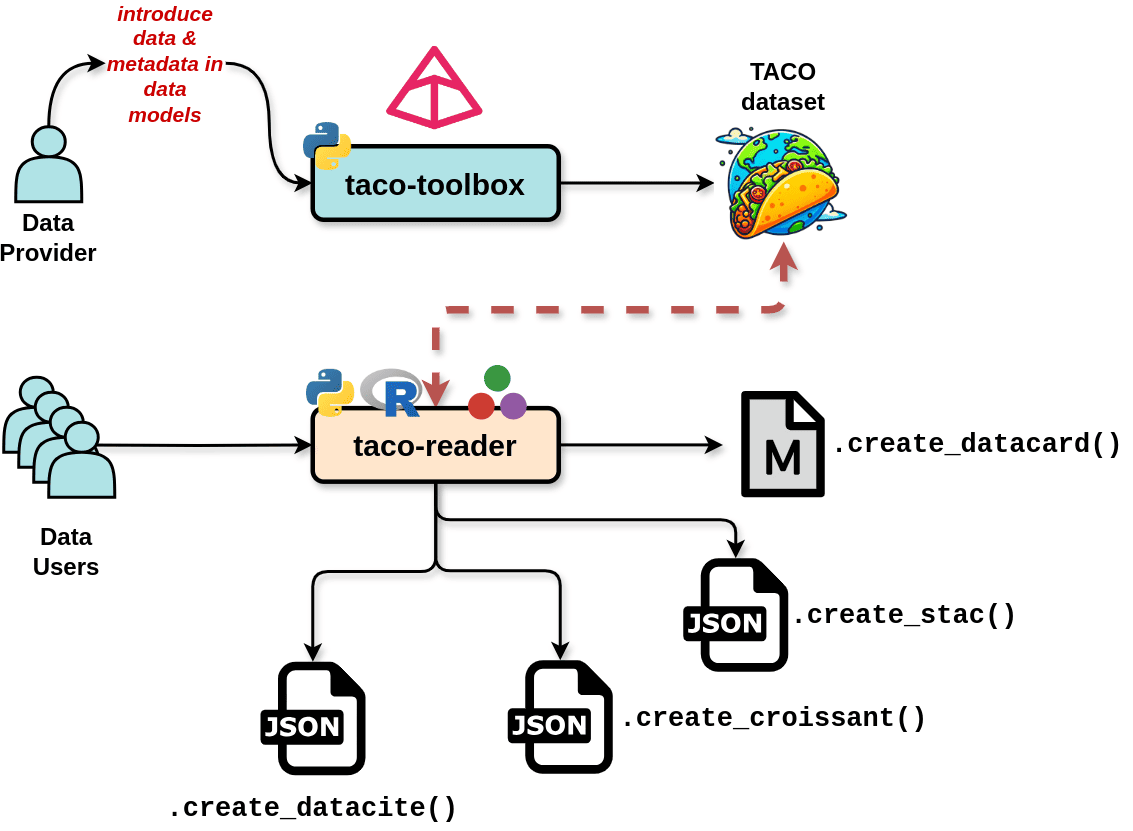
Figure 01: Data provides enter data & metadata in a Pydantic DataModel. The taco-toolbox then generates a TACO-compliant dataset. The data users by using the “taco-readers” can subsequently extract the metadata and convert it into Markdown, JSON, or JSON-LD files, ensuring compatibility with various metadata specifications.
- Accessibility: TACO organizes datasets as collections of samples with similar data and metadata stored in Tortilla files. The dataset structure has two levels: (1) Collection, and (2) Sample. A
Collectiondescribes metadata at the dataset level and helps search engines find datasets on the web and for data users get a general idea of what the dataset is about. Data users can obtain the DatasetCollectionmetadata in one or multiple specifications, as discussed in the Findability section. TheSamplerepresents the fundamental unit of a dataset, encapsulating a single data instance.
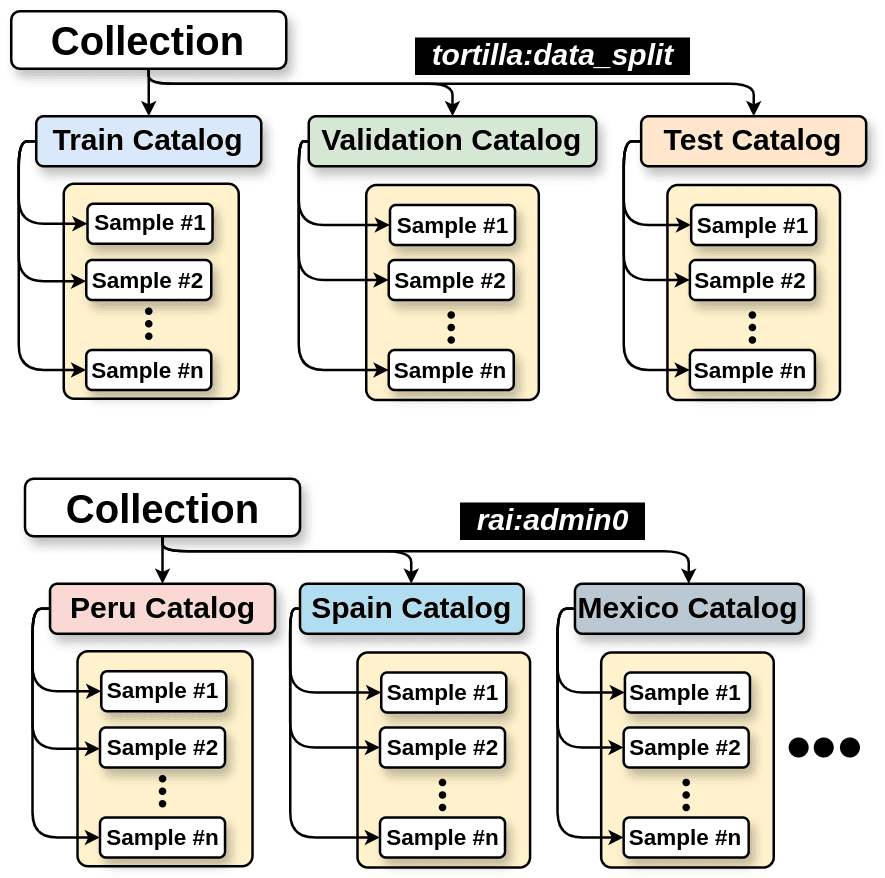
Figure 02: TACO toolbox adopts a structure similar to STAC, organizing the data into collections, and samples. Users can use different fields to split the dataset and create “Catalogs” on-the-fly.
-
Interoperability: TACO uses Tortilla in the backend, which provide fast partial and parallel reading capabilities. See Tortilla specification for more details.
-
Reusability: Since each Tortilla is represented as a DataFrame at the top level, integration between TACO-compliant dataset can be achieved through a simple concatenation operation.
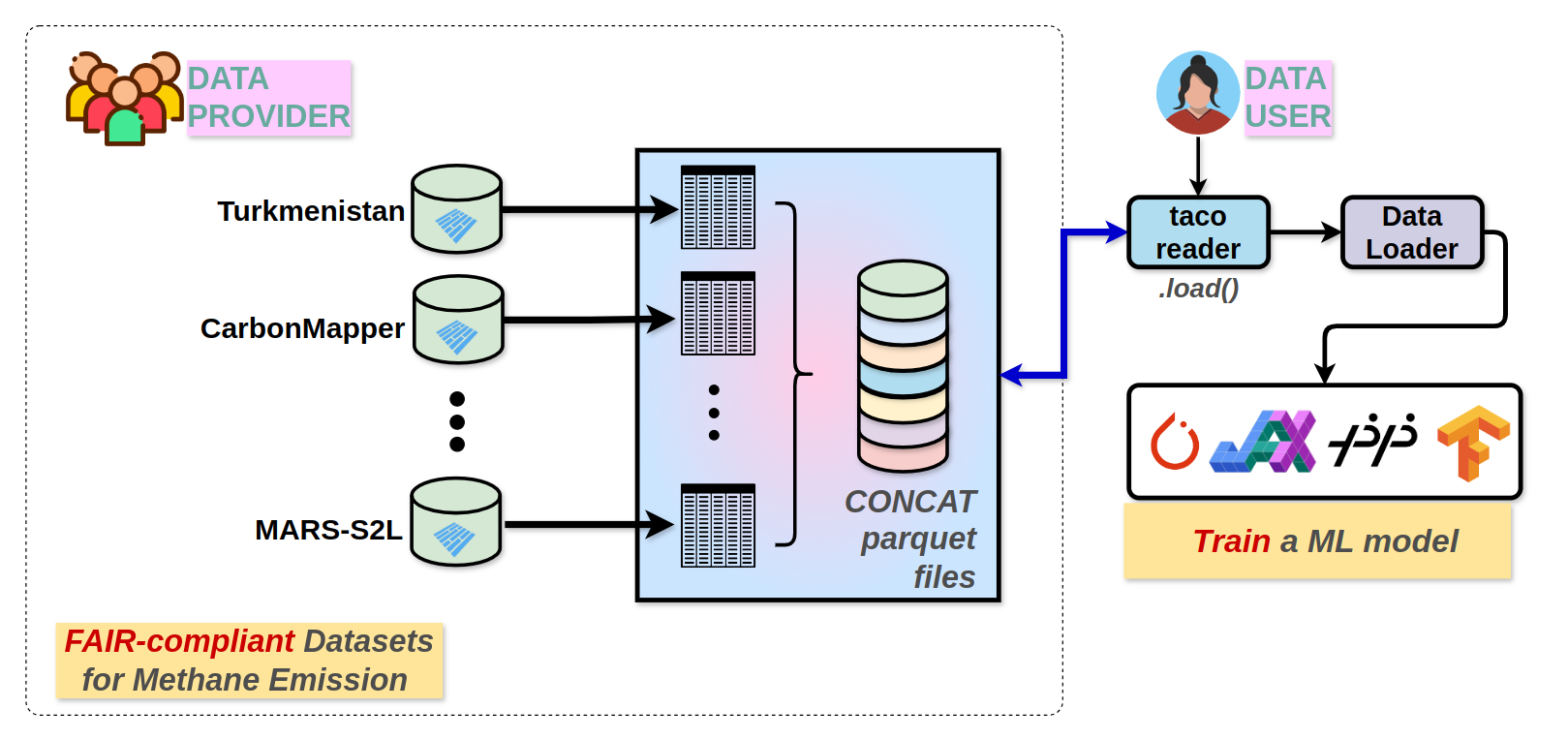
Figure 03: This example demonstrates the integration of all methane emission datasets.TACO facilitate the development of universal data loader. The blue line illustrates the connection between data users and providers through client libraries (taco-reader).
Goals
The primary goals of the TACO specification are:
-
Standardization: Establish a common structure and metadata format for EO datasets.
-
FAIR Compliance: Ensure all datasets align with the FAIR principles to improve data usability and facilitate broader data sharing.
-
Support for Responsible AI: Incorporate fields that align with Responsible AI principles, ensuring that datasets are not only scientifically sound but also ethically compliant.
-
User-Friendly Structure: Organize datasets into a clear hierarchical structure (Collection and Sample) to facilitate easy navigation and retrieval of data.
-
Efficient Data Handling: Utilize the capabilities of Tortilla files for efficient partial reading and parallel processing to improve data access and analysis.
Format
This is version 0.5.0 of the TACO specification. Future versions MUST remain backward compatible with this one. The mandatory fields are:
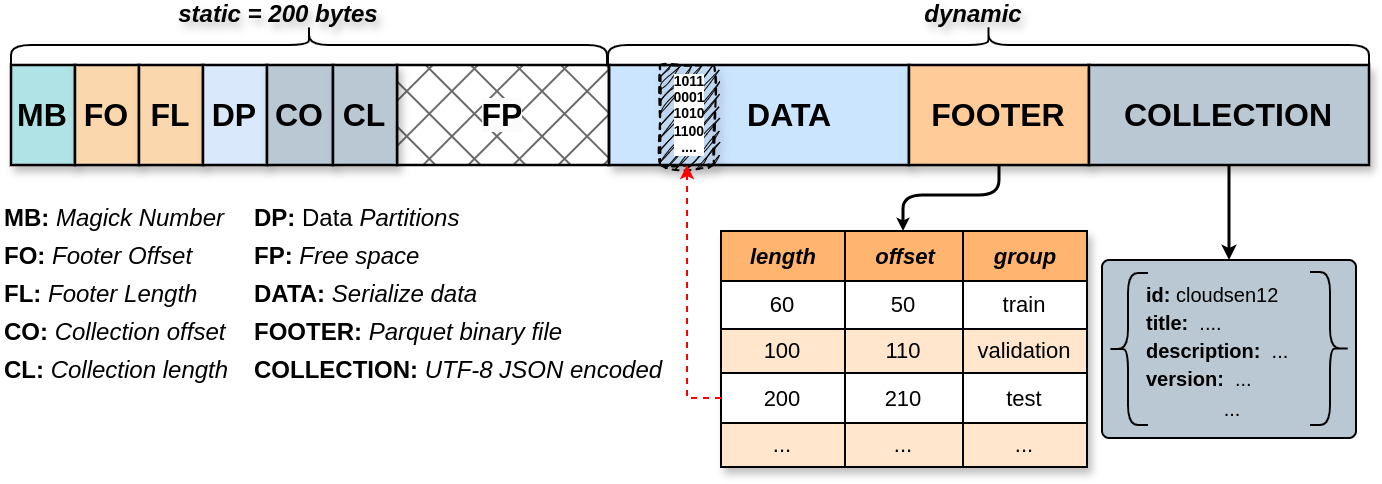
Figure 04: This diagram visually represents the internal structure of a TACO file, highlighting how data and metadata are organized within the file format.
TACO extents the Tortilla specification by adding three fields (see bellow). With these changes, the available free space is reduced to 158 bytes, compared to 174 bytes in Tortilla.
The Magic Number (MB)
A 2-byte identifier at the start of each file (#y in hex) ensures that the file is recognized as a valid TACO format.
int.from_bytes(b'WX', byteorder='little')
The Collection offset (CO)
An 8-byte field indicating the starting position of the collection metadata within the file.
The Collection length (CL)
An 8-byte field specifying the size of the collection metadata in bytes.
The COLLECTION
A TACO Collection is simply an JSON object in UTF-8 encoding. The TACO Collection specification defines a set of common fields to describe a dataset. These fields contain information about data structure, the tasks, the providers, etc. Some fields can be automatically generated using TACO-toolbox, while others must be manually configured by the data provider. TACO Collection can be converted to a STAC Collection, Croissant, or DataCite metadata using the TACO-readers. The mandatory and optional fields that need to be filled by the data provider are:
| Field | Type | Required | Details |
|---|---|---|---|
| id | String | yes | A unique identifier for the dataset. |
| taco_version | String | yes | The version of the TACO specification. |
| dataset_version | String | yes | Version of the dataset. |
| description | String | yes | Description of the dataset. |
| licenses | List of strings | yes | License(s) of the dataset, it is recommended to use SPDX License identifier. Various licenses can be used to describe the dataset. |
| extent | Extent Object | yes | Spatial and temporal extents. |
| providers | List of Person objects | yes | A list of persons, which participated in the creation of the dataset. |
| title | String | no | Title of the dataset. Maximum length is 250 characters. |
| keywords | List of strings | no | List of keywords describing the dataset. |
| curators | List of Person objects | no | A list of persons responsible for converting the dataset to TACO compliance. |
| task | Task Object | no | The TACO specification defines a set of explicit tasks. This field refers to the task most relevant to the dataset. |
| split_strategy | Split Strategy Object | no | The split strategy is a string chosen from an explicit list of method names. |
| discuss_link | HyperLink Object | no | RECOMMENDED. A link to a discussion forum or other resource where users can discuss the dataset. |
| raw_link | HyperLink Object | no | Provides a link to the raw dataset if it was not created in the TACO-native format. |
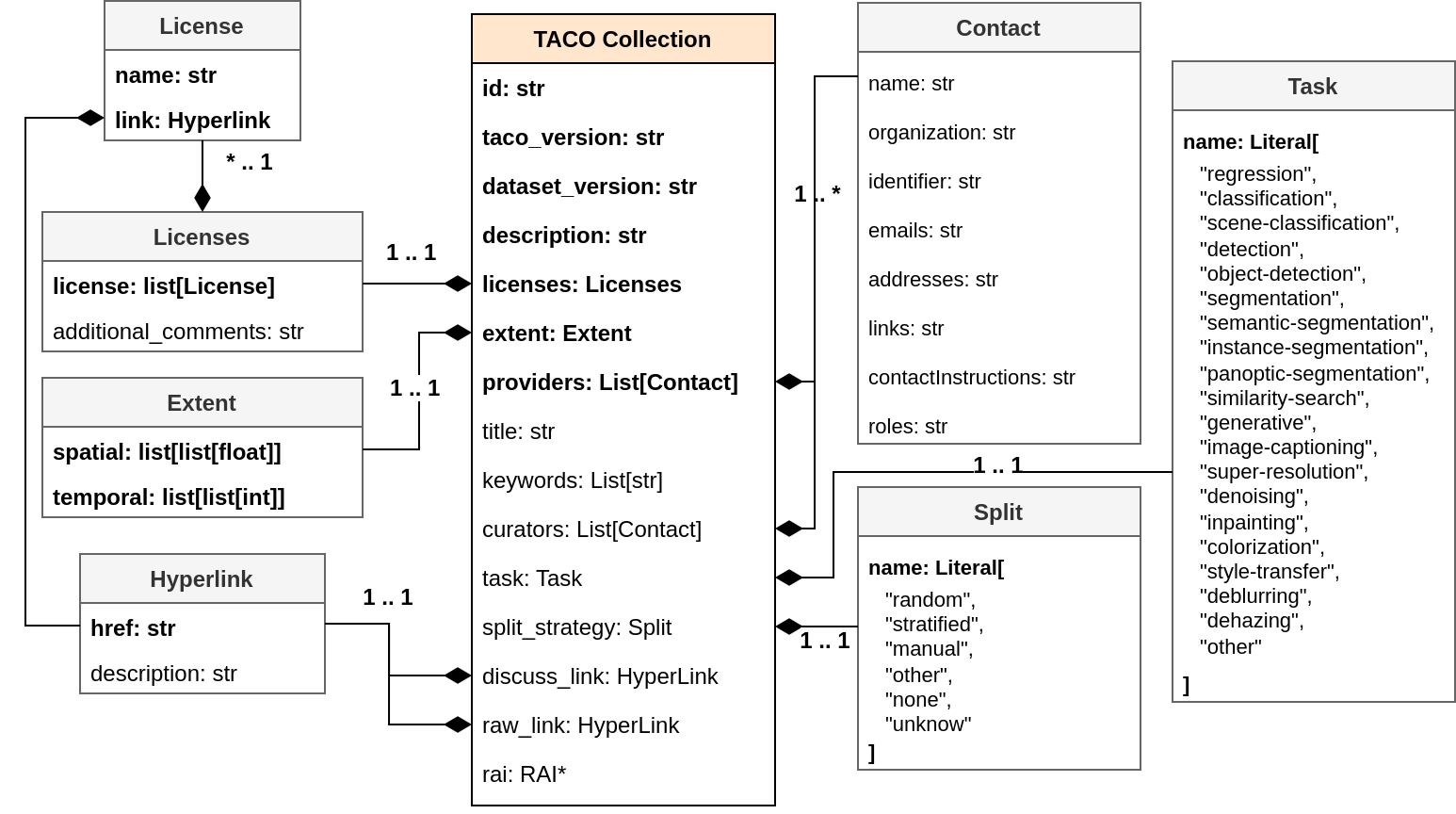
Figure 05: TACO Collection Schema, highlighting core metadata fields such as licensing, spatial and temporal extents, dataset provider, and versioning information for both the dataset and TACO. Other fields shown are RECOMMENDED but not mandatory. The Responsible AI (RAI*) fields are highly RECOMMENDED for documenting potential biases and ethical considerations related to the dataset.
TACO Sample
In TACO, a sample consists of a single data point. The binary data is located within the DATA Pile section, while the metadata is found in the FOOTER section. Refer to the Tortilla specification for more details.
TACO Extensions
Extent Object
Describes the spatial and temporal coverage of the entire dataset. Both spatial and temporal extents are required.
| Field | Type | Required | Description |
|---|---|---|---|
| spatial | List of List of numbers | yes | Represents the spatial extent of the dataset. It contains a list of lists, where each inner list defines a bounding box as [xmin, ymin, xmax, ymax] in the EPSG:4326 coordinate system. |
| temporal | List of List of integer | yes | Represents the temporal extent of the dataset as a nested list. Each inner list contains two integers: the start and end dates, expressed in milliseconds since the Unix Epoch (January 1, 1970, 00:00:00 UTC). Example: [[1672567200000, 1704067199999]] for a dataset spanning from January 1, 2023, 10:00:00.000 AM UTC to December 31, 2023, 11:59:59.999 PM UTC. Multiple inner lists would indicate multiple distinct temporal extents within the dataset. |
Contact Extent Object
The Contact Object is based on the STAC Extension proposed by Matthias Mohr. It identifies and provides communication details for a person or organization responsible for a resource.
| Field | Type | Required | Description |
|---|---|---|---|
| name | String | If organization is missing | Name of the responsible person. |
| organization | String | If name is missing | Organization or affiliation of the contact. |
| identifier | String | No | Unique identifier for the contact. |
| position | String | No | Role or job title within the organization. |
| emails | List of Info Objects | No | Email addresses for contacting the responsible party. |
| contactInstructions | String | No | Additional instructions for contacting the responsible party. |
| roles | List of strings | No | Duties, functions, or permissions associated with this contact. |
Info Object
The Info Object provides contact information and its associated roles. It is used for phone numbers and email addresses.
| Field | Type | Required | Description |
|---|---|---|---|
| value | String | Yes | The actual contact information (e.g., phone number or email address). |
| roles | List of strings | No | The type of contact information, such as home, work, or fax. |
Hyperlink Extent Object
The Hyperlink Object defines a URL and its associated description. The URL must be validated according to RFC 3986, ensuring it conforms to standard URI syntax.
| Field | Type | Required | Description |
|---|---|---|---|
| href | String | Yes | The URL of the linked resource. Must be a valid URI according to RFC 3986. |
| description | String | No | A brief explanation or context for the hyperlink. |
Task Extent Object
The Task Extent Object defines the machine learning task associated with a dataset. The task field is a string selected from a predefined list, where each task specifies distinct input and target tensor characteristics. This task classification is intended to be consistent with mlm:tasks.
| Field | Type | Required | Description |
|---|---|---|---|
| task | String | Yes | The type of machine learning task. Must be one from the predefined tasks list. |
Supported Tasks:
-
Regression: Generic regression that estimates a numeric and continuous value.
-
Classification: Generic classification task that assigns class labels to an output.
-
Scene Classification: Specific classification task where the model assigns a single class label to an entire scene/area.
-
Detection: Generic detection of the “presence” of objects or entities, with or without positions.
-
Object Detection: Task corresponding to the identification of positions as bounding boxes of object detected in the scene.
-
Segmentation: Generic tasks that regroups all types of segmentations tasks consisting of applying labels to pixels.
-
Semantic Segmentation: Specific segmentation task where all pixels are attributed labels, without consideration for segments as unique objects.
-
Instance Segmentation: Specific segmentation task that assigns distinct labels for groups of pixels corresponding to object instances.
-
Panoptic Segmentation: Specific segmentation task that combines instance segmentation of objects and semantic labels for non-objects.
-
Similarity Search: Generic task to identify whether a query input corresponds to another reference within a corpus.
-
Generative: Generic task that encompasses all synthetic data generation techniques.
-
Image Captioning: Specific task of describing the content of an image in words.
-
Super Resolution: Specific task that increases the quality and resolution of an image by increasing its high-frequency details.
-
Denoising: Task that removes noise from an image or signal.
-
Inpainting: Task that reconstructs missing or damaged portions of an image.
-
Colorization: Task that adds color to a grayscale image.
-
Style Transfer: Task that applies the visual style of one image to another image while preserving its content.
-
Deblurring: Task that sharpens an image by removing blur.
-
Dehazing: Task that removes haze or fog from an image to improve visibility.
-
General: A broad category encompassing various tasks not specifically listed above.
Split strategy Extent
The Split Strategy Extent Object defines how the dataset is divided into training, validation, and testing subsets. The split_strategy field is a string representing the chosen splitting approach.
| Field | Type | Required | Description |
|---|---|---|---|
| split_strategy | String | Yes | The dataset splitting strategy. Must be one from the predefined tasks list. |
Supported Split Strategies:
- random: Randomly splits the dataset into training, validation, and testing subsets.
- stratified: Splits the dataset based on a specific property, such as temporal or spatial characteristics (e.g., season or location).
- other: Splits the dataset using a custom-defined pattern.
- none: The dataset does not have a split strategy.
- Unknown: The method used to split the dataset is not known or specified.
Optical Data Extent
The Optical Data Extent provides key information about the sensor and spectral bands of optical remote sensing data. You can specify the sensor (e.g., landsat8oli, sentinel2msi) and optionally subset the bands (e.g., landsat8oli[B01,B02]). If a recognized sensor is provided, the TACO Toolbox will automatically populate the corresponding bands.
| Field | Type | Required | Description |
|---|---|---|---|
| sensor | String | No | The sensor that acquired the data. A subset of bands can be specified in brackets after the sensor name: landsat8oli[B01,B02]. Supported sensors: - landsat1mss - landsat2mss - landsat3mss - landsat4mss - landsat5mss - landsat4tm - landsat5tm - landsat7etm - landsat8oli - landsat9oli - sentinel2msi - eo1ali - aster - modis |
| bands | List of SpectralBand | No | A list of spectral bands. If not provided directly, it will be automatically populated based on the sensor field if the sensor is recognized. |
Spectral Band Object
The spectral band object describes the characteristics of individual spectral bands for a given sensor.
| Field | Type | Required | Description |
|---|---|---|---|
| name | String | Yes | The name of the band (e.g., “B02”, “red”). |
| index | Integer | No | The index of the band. |
| common_name | String | No | The common name for the band (e.g., “blue”, “green”). |
| description | String | No | A description of the band. |
| unit | String | No | The unit of measurement for the band’s values. |
| center_wavelength | Float | No | The central wavelength of the band. |
| full_width_half_max | Float | No | The full width at half maximum (FWHM) of the band, a measure of its spectral resolution. |
The Label extension
The Label Extension offers a standardized framework for defining and describing the labels used in a dataset. It commits this through the Labels object, which contains a collection of LabelClass objects. Each LabelClass represents a distinct category or class within the dataset.
Labels Object
| Field | Type | Required | Description |
|---|---|---|---|
| label_classes | List of LabelClass objects | Yes | A list of LabelClass objects defining the label classes. |
| label_description | String | No | An optional overall description of the labels. |
LabelClass Object
| Field | Type | Required | Description |
|---|---|---|---|
| name | String | Yes | The unique name of the label class (e.g., “car”, “building”). |
| category | String or integer | Yes | The category the label class belongs to. |
| description | String | No | An optional description providing more information about the label class. |
| bbox | Bool | No | The bbox field consists of four numerical values that define the spatial boundaries of an object within an image. The first value represents the x-coordinate of the bounding box center, normalized by the width of the image (ranging from 0 to 1). The second value indicates the y-coordinate of the bounding box center, also normalized by the height of the image (ranging from 0 to 1). The third value specifies the width of the bounding box, normalized by the image width, while the fourth value indicates the height of the bounding box, normalized by the image height. |
The Scientific Extension
This extension standardizes how datasets link to related scientific publications, providing metadata for proper citation and referencing. The Scientific Extension is based on the STAC Extension proposed by Matthias Mohr.
Scientific Object
| Field | Type | Required | Description |
|---|---|---|---|
| doi | String | No | The Digital Object Identifier (DOI) of the dataset. |
| citation | String | No | The full citation of the dataset in BibTeX format. |
| summary | String | Yes | A brief summary of the dataset. |
| publications | List of Publication | Yes | A list of Publication objects representing related scientific works. |
Publication Object
| Field | Type | Required | Description |
|---|---|---|---|
| doi | String | Yes | The Digital Object Identifier (DOI) of the publication. |
| citation | String | Yes | The full citation of the publication in BibTeX format. |
| summary | String | Yes | A brief summary or abstract of the publication. |
The RAI Extension
This extension, based on the Croissant RAI specification (http://mlcommons.org/croissant/RAI/1.0), provides essential metadata fields for documenting Responsible AI (RAI) considerations associated with a dataset. It focuses on data lifecycle, potential biases, limitations, and intended use cases.
RAI Object
| Field | Type | Required | Description |
|---|---|---|---|
| rai:dataCollection | String | No | Describes the data collection process. |
| rai:dataCollectionType | String | No | Specifies the method of data collection (e.g., “Surveys”, “Web Scraping”, “Focus groups”, “Self-reporting”). |
| rai:dataLimitations | String | No | Describes known limitations of the dataset, including potential issues related to generalization, data quality, or data sources. |
| rai:dataBiases | String | No | Describes any known or potential biases in the dataset. |
| rai:useCases | String | No | Describes the intended use cases for the dataset (e.g., “Training”, “Validation”, “Testing”, “Fine Tuning”). |
| rai:personalSensitiveInformation | String | No | Indicates the presence of personal or sensitive information within the dataset and its type (e.g., “Gender”, “Age”, “Socio-economic status”, “Location”). |
| rai:dataPreprocessingProtocol | String | No | Describes the steps taken to preprocess the data, such as cleaning, normalization, or feature engineering. |
| rai:dataAnnotationProtocol | String | No | Describes the process used to annotate the data, if applicable (e.g., platform used, instructions provided to annotators, number of annotators per item). |
| rai:annotationPlatform | String | No | Platform, tool, or library used to collect annotations by human annotators (e.g., “Amazon Mechanical Turk”, “Scale AI”, “Labelbox”). |
| rai:dataReleaseMaintenancePlan | String | No | Describes the plans for maintaining and updating the dataset, including versioning and deprecation policies. |
| rai:dataCollectionTimeframe | String | No | Specifies the time period during which the data was collected (e.g., “2022-01-01 to 2022-12-31”, “January 2023”). |